


论文解读《Plankton Classification Using Hybrid Convolutional Network-Random Forests Architectures》
Paper Reading
Abstract
本文中,使用CNN来解决浮游生物图像的自动分类问题。首先直接使用CNN对plankton分类,随后用CNN提取特征,用random-forest分类器应用在顶层。
Introduction
Dataset
数据是有Kaggle竞赛提供的标注训练数据与未标注测试数据,尽管使用三通道储存,但是为3通道图像。每张图像只包含一类图像。图像不均匀分布在121个种类中,且每张图像大小不同(40-400像素)。训练30,336张图像,测试130,400张图像。大体上,训练图像比测试图像数量少,因此,需要通过数据增强,来扩大训练数据规模(数量)。
Preprocessing and Data Augmentation
在这部分,讨论在训练前,进行的预处理以及数据增强
Dimensional Uniformity
由Kaggle提供的数据集中,图像的尺寸不同,然而CNN需要输入图像都有相同的维数。由于图像大小为40-400个像素,因此将图像调整为128x128的图像。然而,大部分图像的长宽比例部位1:1,因此进行两个实验:
- 保持长宽比:确保给定图像的两个维数中更大的一个,被规范(scaled)在128个像素中。然而,两个维数中更小的一个很明显,要保持长宽比,则像素会小于128。其剩余空间用白色背景进行填充,因为其与图像背景更合适
- 放弃长宽比:使每张图像的每个维度都scale到128x128(不管原始维度)。则这将造成许多图像受到扭曲(特别是矩形图像)
在训练卷积网络上,两种transformations方法都得到使用,发现在训练与验证损失上没有明显差别。决定在本文的CNN(ClassyFireNet)保持长宽比,在另一个网络(GoogLeNet)放弃长宽比
Filtering Images
在部分实验中,本文也在原始图像上使用了canny-edge检测,使用其最终的edge-images进行训练。目的是在transformation的结果中,去除图像中的噪声。然而,经过滤波(filter)的数据集没有表现出比原始数据更好的效果。推测是plankton图像有texture loss,导致convolution不是那么有效。
Data Augmentations
由于测试数据在数量上比训练数据大,因此在没有通过人工数据增强来增大数据数量的前提下,使模型泛化能力强。尝试了许多数据增强方法:
- 旋转(rotation)(度到360度,每次20度的增量)
- 区域放大/缩小(zoom)(因子1/1.13,到1.3)
- 剪切变换(shearing)(-20度到20度)
- Flipping
- 转换
尽管实时数据增强,总是优于offline/batch-processing数据增强,因为Caffe限制,只能用offline data augmentation完成rotation, zooming和shearing,而不能使用实时data augmentation,而flipping与translation为实时
Training/Validation Split
使用85%的原始数据用来训练,剩下的15%用来验证。数据点是随机选择的。如果一张图像用来训练,那么其augmentation也都用来训练。这做法防止了一张图片用来做训练,其转换用来验证。
Loss function
本部分说明了CNN的loss function的最小化以及随机森林。在loss function中的改动改变了分类器基本的优化目标
Logarthmic Loss
这次竞赛中,评价的主要标准是对所有测试样本计算log-loss:
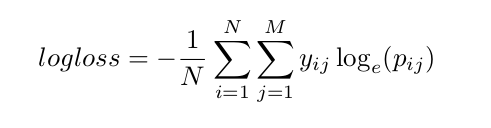
N表示测试样本个数,M表示种类个数,p_{ij}表示测试样本i属于类别j的可能性,y_{ij}是1表示样本i确实属于类别j,否则为0
小的loss表示分类器预测正确类别的准确率(平均的情况下)。
Classification Rate
另一个对分类问题,有用且通用的方法是分类比例(classification rate),数据点的选择使分配给正确类别的正确率最高。loss评判标准对于分配给正确类别可能的实际值是不变的,只检查分配给正确类别的可能性是否高过其他。然而,这标准不是用来CNN优化的目的的,是默认Random Forests训练的默认标准。
Network Architecture
介绍了网络结构,先从少量的卷积层将起,再形成深层网络
4 convolution, 1 fully-connected layers
第一次尝试训练CNN,用简单的4层卷积层(conv3-64each)和1层全连接层(FC-256)开始,得出121类别的Softmax预测。因为train loss和validation loss并不是不相关,因此我们得出模型有很低的容量,甚至在没有data augmentation的情况下,overfitting是不可能的。需要更大容量的深层模型
5 convolution, 2 fully-connected layers
使用了默认的CaffeNet,只在输入层与输出层进行改动(数据尺寸以及类别数量)。在13-14 epochs训练后有overfit,训练loss为0.81,验证loss为1.18。尝试移去LRN层,在性能上没有差别。因为在drop layer的前提下,仍然出现overfit,在训练图像与测试图像的data augmentation上,减少间隙,增加rotation图像。通过对每张图像增加45度增量,增加了总的数据集将近因素为7。对增强的数据集训练10 epochs,在训练与测试loss上,都达到0.94。因为train loss与validation loss达到相似的情况,因此使用更深的模型
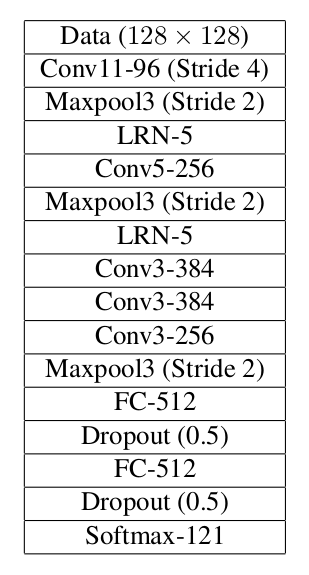
ClassyFireNet- 8 conv, 2 FC
这是最终convolutional网络的第一个部分。该网络参考了VGGNet。该网络的思想是在低层上辨别更低层次特征,在高层上建立更高层次特征。
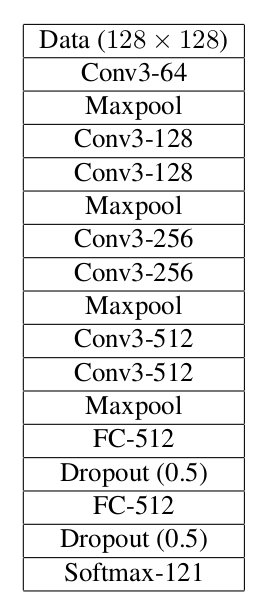
在没有data augmentations的情况下训练这architecture,能容易overfit。为了解决overfitting问题,增加rotations(20度增量),translation(在x和y方向上随机加减4个像素点,每个方向可能性相同)以及flipping(Bernoulli,p=0.5)作为data augmentation。在之前已经训练的权值上,继续训练网络5-10 epochs(epoch of data augmentation)。为了进一步解决overfitting,引入更多的augmentation(zooming以及shearing)。继续训练,发现validation loss达到0.794。用Kaggle得到test loss为0.785。
GoogLeNet
multi-scale CNN的引入,训练得到naive和modified的GoogLeNet实现。对于naive,表示某种optimizations(例如batch normalization并没有使用到)。而且这里的权值使用Xavier算法进行初始化,而不是用gaussion。对于modified,在第一层卷积与最后一层average pooling使用8x8的kernel。在softmax层使用121类而不是1000类。这些改变使我们能够用128x128像素图像,预测121类不同plankton。使用全部data augmentation,对validation可达到0.817。Kaggle的test loss为0.798。(标注:先用validation验证达到可信的正确率,再使用test实际测试。所以validation是必须的,可从训练集中分离出,而test必须是独立的数据)
Training
本部分说明了通常训练的方式与避免overfitting方法(对于有限数据的CNN,不断重复的问题)
Training Algorithm
在模型中,使用mini-batch stochastic gradient descent with Nesterov momentum。Batch size大小根据不同模型对GPU显存的限制,而通常为32-64个样本。因为batch size与数据集的大小相比,要相对小。momentum为0.9能在训练中减小波动。模型中的所有初始值使用Xavier算法进行初始化。初始用0.01学习率,在原始数据集的10epochs,减少0.9的因子。当validation loss停止改变,learning rate变成更小的值。上述learning rate是针对普通权值的(非偏置bias),偏置bias是2倍学习率。
Regularization
因为有性能的大部分取决于降低overfitting,考虑了很多方法。首先,增加data augmentation是通过减少training与validation loss间的差值提高验证性能的。然而,许多情况下,这个方法泛化能力不强,因此使用在全连接层后放置drop-out层来正则化模型。在ClassFireNet,dropout为0.5性能更优,在GoogLeNet中0.4和0.6性能更优。另外,也用weight decay的值从0.01-0.00001来正则化,发现weight decay为0.0001,性能最好
Strategy
用以下方式训练模型:
- 设计CNN网络
- 用无data augmentation训练
- 如果没有overfitting发生,终止训练,用更深层次网络
- 如果overfitting发生,引入data augmentation,继续训练
- 在data augmentation确定后,调整参数(例如learning rate或者weight decay),然后继续训练
Feature Generation for Random Forests
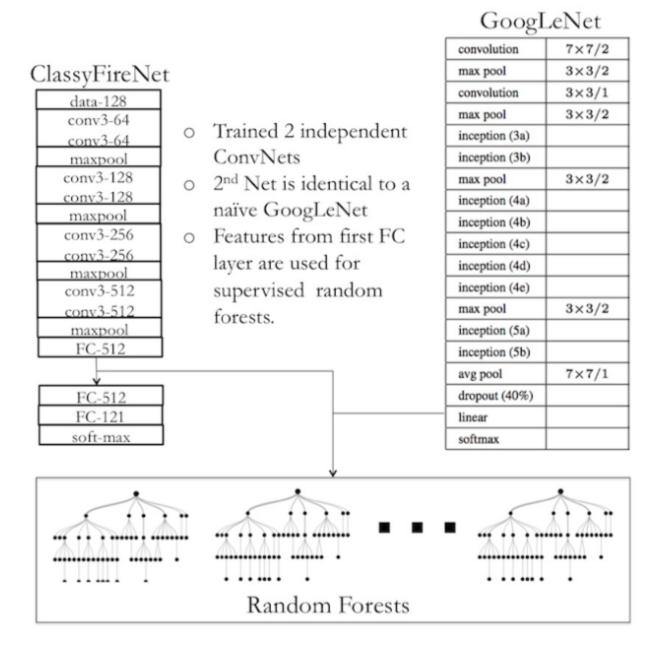
创建了两个CNN,每个CNN的logloss接近0.8,则使用CNN作为feature generation。从ClassFireNet对于整个训练数据中的模型中,在第一个全连接层(ReLU传递)提取512 features,相似地,从GoogLeNet的全连接层提取特征。
从上面两个模型中生成的特征,作为有标签的训练数据输入到random forests分类器中。用random forests分类器,其深度为20-25,有10-100个trees,能够达到很好的validation分类准确率(76-77%)。比较中,两个CNN的准确率为71-74%。然而ramdom forests的预测logloss更低。random forests的优化问题是降低误分率而不是logloss。
Model Averaging
在这点,设置了三个预测集,每个都有相似的性能。然而,random forests是一个非是即否的分类器,其与网络的全连接不同。预测的多样性对整体而言是成功的。图5表示测试样本数量,其是分配给0或1的值的最大。
Results and Conclusions
random forests预测与ClassyFireNet网络的平均模型的结果,logloss为0.75。从CNN中提取出的特征,可用在其他的分类器上,例如SVMs与Grandient Boosting Machines。