


论文解读《Deep Neural Network for Deep Sea Plankton Classification》
PaperReading
Abstract
在本文中,使用深度卷积神经网络,经过data augmentation和regularization,实现分类任务。也使用了code vector(倒数第二个全连接层的输出)完成模型组装。引入了PCA,Ridge和Randomized Ridge模型组装方法,显示了Randomized Ridge模型胜过简单的可能平均方法。通过简单的VGG-like的CNN模型,得到73.90%准确率,在测试集上log loss减到0.938。在模型组装的方法上,可以达到75.80%准确率和log loss为0.857。最近通过组装11个独立的CNN模型,在无label测试数据上可以达到0.772707。
Introduction
CNN适用于图像分类问题,在这里的网络架构与VGG相似,使用了data augmentation,drop regularization,ReLU激活函数和不同的模型组装方法。
Methods
CNN Architecture and Training
VGG架构的主要组成部分:卷积层,ReLU层,max-pooling层,fully-connected层与dropout层。用这些部分将浅层网络组成深层网络。架构分为两个部分:
-
卷积部分:用kernel size为3x3,pad为1的设置效果最好。ReLU是在放置在每卷积层之后,引入非线性。Max-pooling层减少filter结果的size与集中区域信息。使用了2x2的max-pooling。每个max-pooling层之前的[conv-relu]的数量应该为2或1。具体形式为:[[conv-relu]x M]x N
-
全连接层:dropout层放置在每个全连接层之后,来提供正则化放置overfitting。具体形式为:[[fc-relu-dropout]x K]-fc-softmax
由于CNN结构关键部分是convolutional层和fully-connect层,用这两层的数量来描述网络。模型使用Caffe训练,使用Stochastic Gradient Descent优化。
- Data Augmentation: 输入图像调整为80x80,随机crop取为64x64,在训练过程中采用随机flip。另外,也尝试过随机90度rotation
- Dropout: dropout ratio设置为0.5。为了验证dropout层在convolutional layers层的影响,在两层convolution后加上dropout层
- Leaky and Parametric ReLU: Leaky ReLU层的激励function。negative slope中的a为0.1。在这论文中,初始化a=0.25
Model Assembly
模型组装(model assembly)可降低结果的变动性,提高预测准确率。使用以下集中方法assembly不同CNN的模型:
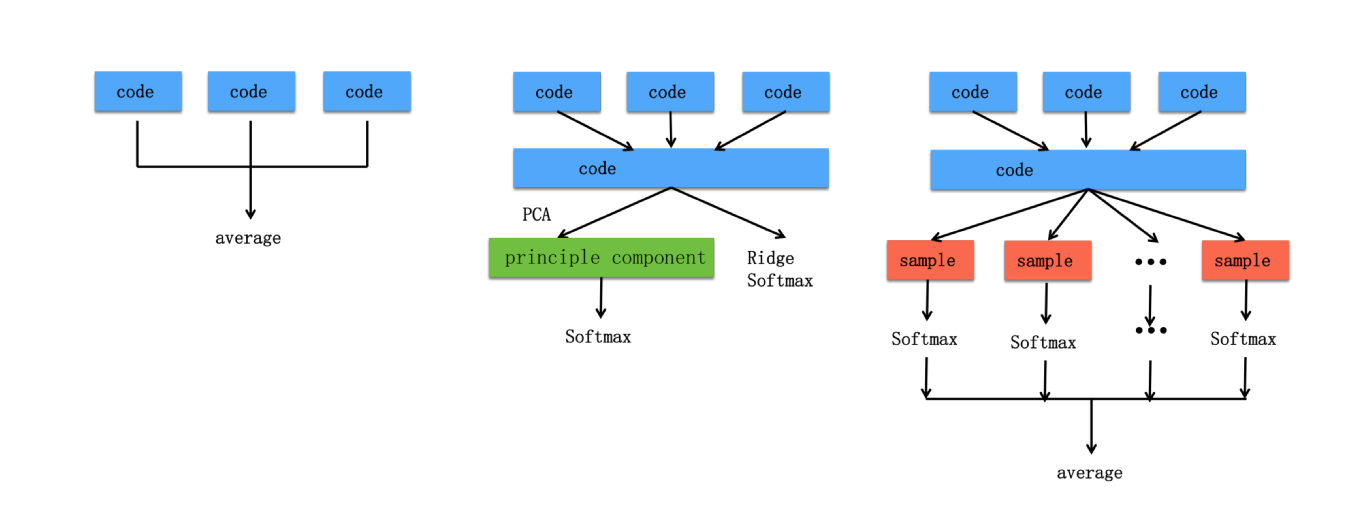
- Probability Average: 最简单的模型组合就是对所有模型的可能性预测求平均
- PCA: 将倒数第二层[fc-relu]层作为code vector,code vector对从CNN中学习到的特征进行总结。PCA model assembly方法首先将从CNN模型中提取的特征作为code vector,随后计算这些特征的第一个K主成分。用这个主成分训练softmax分类器,因为code vectors是相关的,PCA提供了维数降低,原始code vector不相关总结,降低预测误差
- Ridge: L2-penalty也可用来找寻相关特征,Ridge与PCA model assembly相类似,在用L2-penalty形成softmax分类器,非主成分
- Randomized Ridge: PCA与Ridge最终只有一个预测分类器,分类器可能仍有不稳定性。为了解决这个问题,randomized ridge model assembly过程训练了许多softmax分类器,对从code vectors中的特征进行取样,然后这些softmax分类器再集合形成更稳定的预测。对特征的下采样使分类器能力下降,但是不相关性增强。这个方法与Random Forest算法相似,而用softmax分类器代替决策树
Result
Data and Evaluation
有30,000张标注图像,在121个类中,130,000张无标注测试图像。为了比较和评价不同模型和方法,将标注分为3个部分:train(26,000),validation(2,000)和test(2,000)。在data augmentation过程中,图像被调整为80x80,再经过随机crop与flip。模型用training和validation set训练,而log loss和evaluate用test set得出。
用准确率与log loss作为评价标准。log loss为:
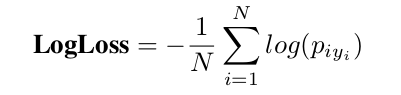
N是validation或test的数量,y_{i}是样本i的真实类别
Result of Single Model
Result of Log Loss and Accuracy
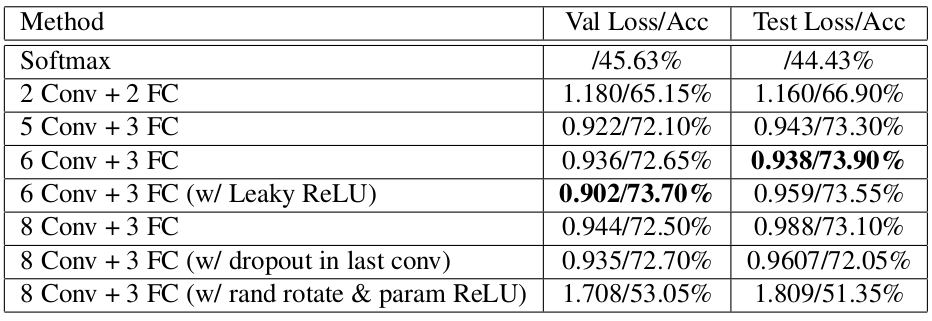
- CNN表现比linear baseline更好
- [6 Conv + 3 FC]效果最好,5 Conv表达性不够,8 Conv的overfitting过多
- 为了解决8 Conv的overfitting问题,在convolutional layer后增加dropout层,dropout提升了log loss的表现,但是对accuracy影响不大
- 另一个解决overfitting问题的方法是在data augmentation中,添加随机rotation。在8 Conv模型中,增加了parametric ReLU,希望ReLU层能够提供更多能量以及更快的学习速度。但是这个方法,造成了更差的效果。可能是因为随机90度rotation对training set增加了过多的噪声。用更小程度的随机rotation可能效果更好
- 为了提升[6 Conv + 3 FC]模型的性能,使用ReLU使其更具表现力与学习速度。结果是,在validation set上有更好的效果,在test set上并没有突出表现
Visualization of CNN Output
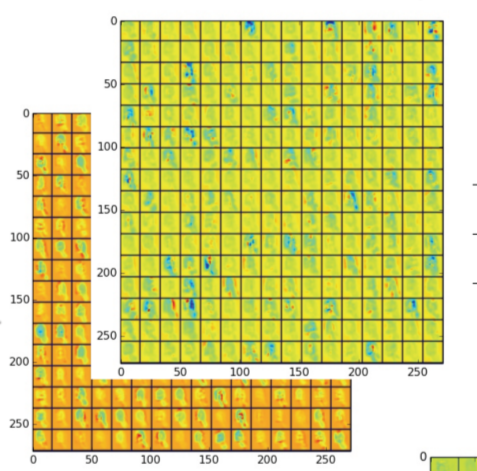
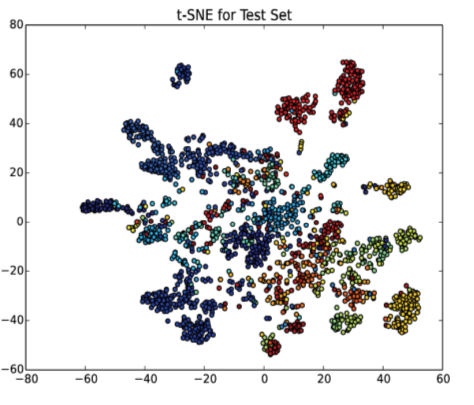
为了对卷积层可视化,将每个convolution层作为样本,用图表示出来。其很清晰地表示了convolution层如何从局部到全局获取图像特征的。在全连接层,用t-SNE图表示code vector。从t-SNE图中,可以看到code vector提供很好的特点来分离与表示每一类。
Result of Model Assembly
将4个[6 Conv + 3 FC]对training set单独训练,对training,validation和test set,用4个模型的code vectors对每个样本手机连接提取特征。用上述方法将code vector组合,最终的code vector维数为2048x4=8192。对于PCA和Ridge模型组合方法,用log loss作为评判标准。
PCA
主成分元素个数K对于训练分类器常用128-4096等。loss在768左右达到最小值,表明K太小,不足以从code vector中提取足够的信息,造成under-fitting。然而过大的K不能减少噪声,造成overfitting
Ridge
与PCA相似,Ridge方法,需要调节L2-penalty正则项lamda,使softmax分类器达到最小loss。如果lamda过小,分类器有过多相关特征,如果lamda过大,正则化太强,造成underfitting。lamda用1e-5到5e-1,得到lamda=1e-1效果最好
Randomized Ridge
在code vector中,1/8的特征得到下采样,再用正则项为lamda为1e-4,输入进softmax分类器中。每次训练一个新的分类器,更新tes set的accuracy与log loss。从图中可以明显看出通过聚聚分类器,性能提升的趋势。聚集100个模型的结果由于probabiliry averaging。
Summary and Comparison
- 虽然PCA和Ridge智能预测一个softmax分类器,但是二者可提升单个模型结果。表示PCA和Ridge方法对降低模型误差有效
- probability averaging在log loss方面优于PCA和Ridge,表示PCA和Ridge的单个分类器仍然有误差
- Randomized Ridge在log loss和accuracy方面优于probability averaging。原因可能是下采样特征只有很少误差,可通过对多个弱分类器形成强分类器,提升预测效果且进一步减少误差
Result in Unlabeled Test data on Kaggle
训练了11个不同的CNN模型,包含了5,6或8层卷积。模型用简单的probability averaging方法在test set测试。
Error Analysis
- plankton图像难以辨认
- 图像虽然是”unknown“,但是图像看起来像plankton
- 图像很模糊
- 图像从不同角度拍摄,在training set中很稀少
Conclusion
Data augmentation和regularizations(dropout等)对CNN模型可减少overfitting与更好generalize