


论文解读《Very Deep Convolutional Networks for Large-scale image recognition》
PaperReading
ABSTRACT
论文中,研究了CNN网络深度对于大规模图像识别准确率的影响。主要工作是通过在一个3x3filter的网络结果中,增加网络的深度,对其进行评价。表明了通过增加网络深度到16-19层权值网络,可以达到重要的提升。其表示能力对其他数据集效果也很好。
INTRODUCTION
随着ConvNet称为计算机视觉领域常使用的方法,许多工作都是对原始框架(AlexNet)进行修改达到更好的正确率。在这论文中,解决CNN设计另一个重要的方面:深度。通过固定了架构中其他的参数,通过逐步增加更多的卷积层,来提升网络的深度,因为是使用3x3的小filter,所以这方案是可行的。
最后,得出了一个高准确率的CNN架构,达到了ILSVRC分类和定位任务的state-of-the-art,而且对于其他的图像识别数据库也达到很好效果,甚至只是作为简单的相关流程来使用(例如用线性SVM类对深度特征分类)
论文中剩下部分的分配:Setc2是说明CovNet配置;Sect3说明图像分类训练和评价的细节;Sect4将配置与ILSVRC分类任务做比较;Sect5总结了论文。
CONVNET CONFIGURATIONS
为了在相同设置下,测量通过增加ConvNet深度所带来的提升,所有ConvNet各层的配置都是使用相同的规则。在本部分,首先说明了ConvNet的具体层次配置,随后在讨论在评价中所使用到的详细配置。最后,讨论设计的不同选择与之前的进行比较
ARCHITECTURE
在训练中,输入图像固定为224x224的RGB图像,唯一的预处理就是在training set上,对每个像素计算,减去RGB的平均值。图像经过一堆的convolution layer,其中使用很小的感受野3x3。在配置中某一层,使用1x1的filter,可以看做是输入通道的线性转换。stride为1 pixel;spatial padding是卷积后空间分辨率的保存,padding为1;spatial pooling为max-pooling,max-pooling为2x2,stride为2。
在一堆不同的卷积层后,是FC层,第一个和第二个是每个4096个通道,第三个包含1000个通道,对应ILSVRC1000个类别,最后是soft-max层。FC在所有网络中都是相同的。
隐藏层(hidden layers)使用了ReLU。另外,所有网络都不包含LRN,因为这些normalisation不能提升效果,而且还造成时间与内存的开销。但是在AlexNet中,使用了LRN层。
CONFIGURATIONS
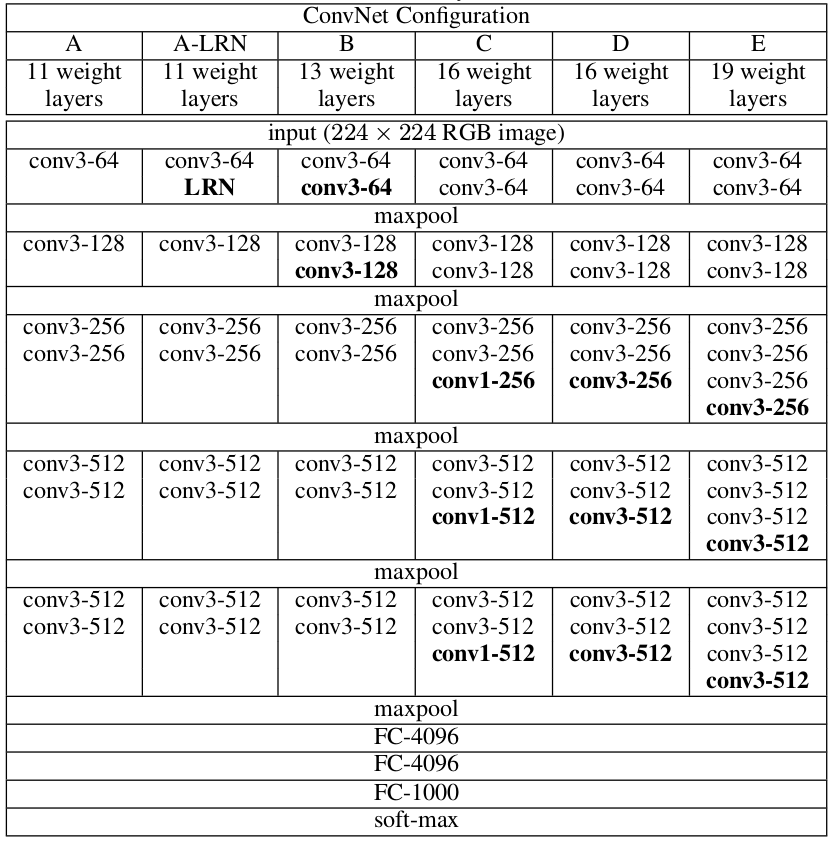
上图为这论文对ConvNet配置的评价,每一列代表一个网络配置。用A-E表示不同网络,所有这些配置都采用上述通用的设置,只有在深度上是不同的。从A(8 Conv + 3 FC)到E(16 Conv + 3 FC)。卷积层的宽度(通道数量)是相当小的,从第一层的64个,然后逐层增加,知道512个。
尽管由于深度更深,然后网络中的权值数目并不会比浅层大卷积网络多。
DISCUSSION
ConvNet配置与AlexNet不同。不使用更大的感受野在第一个卷积层(11x11,stride为4或者7x7,stride为2),在整个网络中,只使用3x3的感受野,步长为1。很明显可以看出两个3x3卷积层的组合,能起到5x5感受野的效果;三个3x3卷积层的组合,能有一个7x7感受野的效果。那么为什么使用3个3x3的卷积的组合,而不是使用单个7x7层呢?首先,论文中使用了3个ReLU(non-linear rectification)层,而不是知识用一个,这个使判决函数判别能力更强。其次,论文降低了参数数量,假设3个3x3卷积的组合有C个通道,该组合的参数为3(3x3xCxC)=27CxC个权值;然而,单个7x7卷积层将有49CxC个参数。这里可以视为在7x7的卷积层上强加正则项,强迫使其分解为3x3的filter(在中间加上了非线性)
1x1卷积层的引入,是一种增加判决函数非线性的方法,而且还不影响卷积的receptive fields(卷积效果)。尽管1x1卷积本质上是在对同一维度空间的线性投射(输入与输入通道数是相同),非线性是rectification函数引入的。在NIN框架中,1x1卷积层收到使用。
小size的convolution filter收到广泛关注。
CLASSIFICATION FRAMEWORK
说明ConvNet训练和评价的细节
TRAINING
ConvNet训练过程与AlexNet相似(除了从多尺度训练图像的输入crops采样),训练就是通过mini-batch gradient descent伴随momentum,优化多项式逻辑回归目标。batch size设置为256,momentum为0.9。训练是用weight decay正则化(L2 penalty设置为5x10-4),对最初的两个全连接使用dropout(dropout比例设置为0.5)。learning rate初始设置为0.01,当验证集正确率不变时,learning rate除以10。总共,learning rate下降3次,在370K次(74echos)。尽管ConvNet的参数数目与深度都比AlexNet多,但是ConvNet只需要更少epoch聚集,是由于隐藏的正则项与某些层的预训练。
网络的权值初始化很重要,因为差的初始化可能停止学习,由于深层网络的不稳定性。为了解决这个问题,以网络A开始,由于网络很浅,可以通过随机初始化。然后,要训练更深层的结构时,用网络A初始化前四层卷积层和最后三层全连接层,中间的层随机初始化。不降低learning预初始化的各层,让其随着学习进行改变。对于随机初始化的各层,使用均值为0,方差为10-2,采样权值。bias初始化为0。随后发现,值得注意的是,可能可以使用随机初始化这些权值而不用预训练。
为了得到固定大小为224x224的ConvNet输入图像,对rescaled training图像进行随机crop。为了继续增强training set,这些图像经过随机horizontal flipping与随机RGB color shift。
- training image size:S为经过了crop,等轴的rescaled training图像的最小的边。当crop size固定为224x224,S不能取少于224的值。对于S=224,crop能获取整副图像的统计特性,能完全包含训练图像的最小边。对于S»224,crop将会对应图像的一小部分,包含图像的小物体或者物体的一部分。
有两种方法,设置training scale S。第一种是固定的S,对应单scale训练(仍能表达multi-scale图像的统计特性)。在实验中,评价了用两种固定的S训练的模型:s=256(这个值比较通用)与S=384。基于给定的ConvNet配置,首先用S=256来训练网络。为了加速S=384网络的训练,用S=256的预训练权值进行初始化,再用更小的初始learning rate为10-3。
第二种设置S方法是multi-scale训练,S在[256,512]范围内,每张图像都用随机S单独rescale。因为图像中的物体是不同size的,在训练时考虑到这方面是有效的。这也可认为是用scale jittering做的提升,模型可对一定范围scale的物体进行识别。为了加快速度,对相同结构下的,用S=384预训练的单scale模型进行fine-tune。
TESTING
在训练时,对于已训练的ConvNet和一张输入图像,可用以下方式:首先,用Q表示等轴的rescaled的预训练的最小边。测试Q不一定要与训练scale S相同(分析不同个的Q值对应的每个S来提升性能)。网络应用在rescaled test图像,通过与OverFeat相似的方式。也就是说,圈连接层转换为卷积层(第一个FC层为7x7卷积层,最后两个FC层为1x1卷积层)。得到的fully-convolutional网络应用在整个图像上(未crop)。其结果是一个类别分数map,表示通道的序号对应的类别序号。最终,要得到固定size的类别得分向量,class score map是空间平均的(sum-pooled)。另外,也用horizontal flipping来augmenta test图像。原始图像和flipped图像的平均,通过softmax来得到图像的最终分数。
因为full-convolutional网络应用在整张图像,在测试时,不必对multiple crops采样,如果对每个crop重新计算则浪费效率。同时,用大的crops集合,可以提高准确率,相比fully-convolutional net,它得到更好的采样。另外,multi-crop评价是对dense评价的补充,因为不同的卷积边界条件:应用了crop,convolved feature map就要补零,然而对于来自一张图像相邻部分的同一crop补零的dense评价,增强了全局感知野,获取更多信息。然而在实际情况中,multi-crop增加了计算量,也不一定能提升准确率。最后也用了50crops每个scale(5x5 regular grid with 2 flips),总共3个scale,150个crops,与4个scale144crops作比较。
IMPLEMENTATION DETAILS
方法是由Caffe实现的,但是包含了许多带动,使其能够在多GPS上训练和评价,也包括multi-scale的uncrop图像的训练和评价。Multi-GPU训练使用数据并行,将数据分离给不同的batch给多个GPU,每个GPU并行处理,当GPU将batch gradients计算好,则进行平均,得到全部batch的gradient。GPU上gradient计算同步,因此结果和单GPU相同。
ConvNet对网络的不同层,使用模型与数据并行。
CLASSIFICATION EXPERIMENTS
大多数实验中,使用validation set作为test set。
SINGLE SCALE EVALUATION
刚开始,评价single scale的单个ConvNet模型。test图像设置为:如果S为固定值,则Q=S;如果S在一范围内,Q=0.5(S_min+S_max)。
首先,在没有normalisation层的情况下,LRN的引入没有提升网络A的性能。因此在更深的网络B-E中,不使用normalisation。
其次,随着ConvNet层数的增加,分类错误降低。尽管C和D的深度相同,但是使用3个1x1卷积层的网络C比使用3x3卷积层的网络D效果差,这说明了虽然额外的非线性确实其作用了,但是用non-trivial(具有一定复杂度)的感受野更能获取空间内容(D比C更好)。当结构层数达到19层时,结构错误率不发生变化,但是如果有更大的数据集,更深的网络能有更好的效果。另外,论文也比较了网络B与浅层的5层5x5卷积网络(与B相似,只是将B中两个3x3卷积网络替换为单个5x5卷积),则浅层网络的top-1错误率比网络B高出7%,证明了小卷积核的深层网络,比大卷积核的深层网络更有效。
最后,在训练时,mutile-scale(S属于[256,512])比固定的S值,能取得更好的效果,尽管在测试时使用single scale。这个证明了变化的scale(scale jittering)对于获取不同multi-scale图像统计特性更有效果。
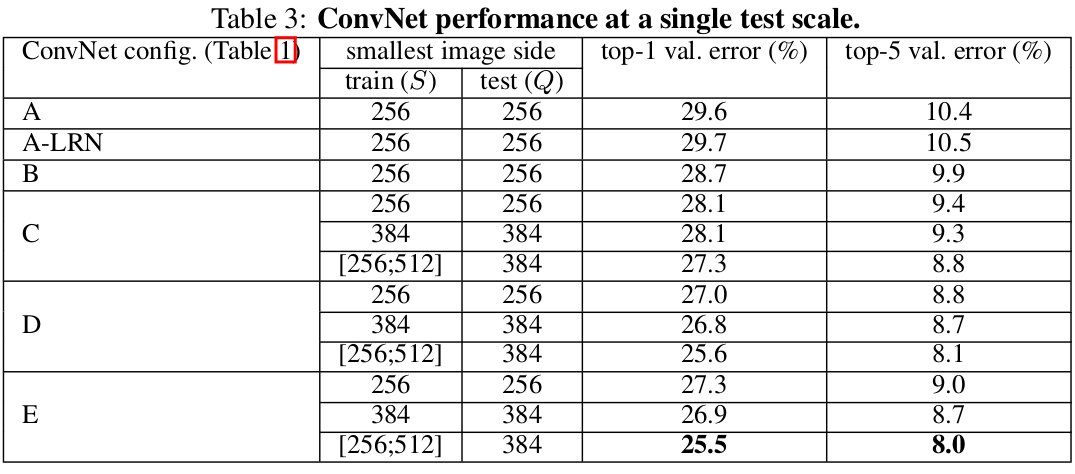
MULTI-SCALE EVALUTATION
对single-scale已经评价完了,则对测试时jittering scale(浮动scale)进行评价。即在测试时,使用不同的rescaled图像。考虑到training图像和testing图像的scale不同,可能造成性能的降低,用固定S训练的模型,将用三种不同的接近training图像的test图像size进行评价:S-32,S,S+32。同时,用scale jittering训练允许测试时有大的scale范围,所以用S为[S_min,S_max]训练时,可用Q为[S_min,0.5(S_min+S_max),S_max]评价。
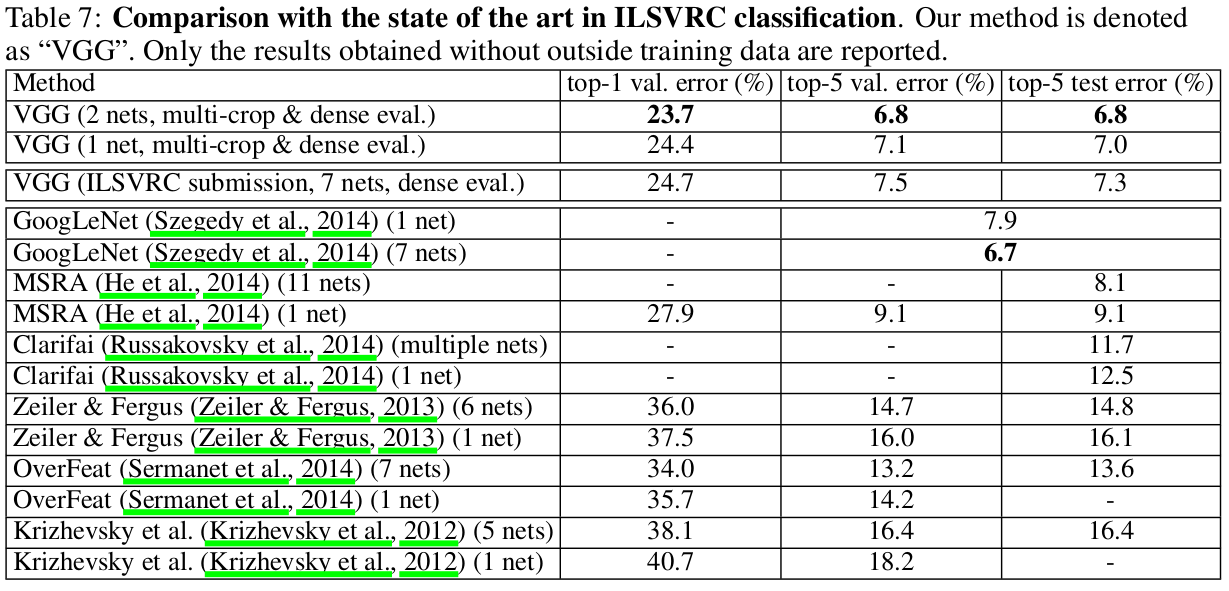
结果表明,测试时scale jittering可以有更好的性能。对于之前性能最好的网络D和E,scale jittering比用最小S边训练的效果更好。在validation set上最好的单个网络,top-1/top-5 error为24.8%/7.5%。而test set,E可达到7.3%的top-5 error。
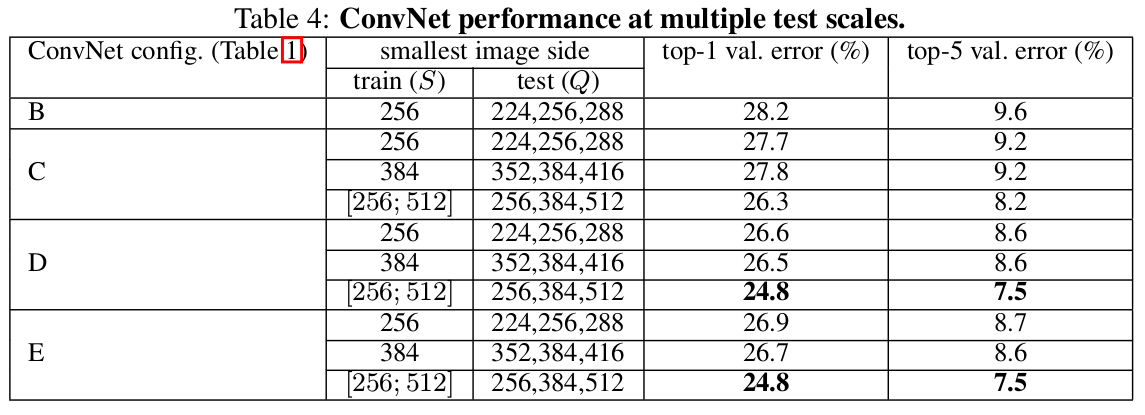
MULTI-CROP EVALUATION
比较multi-crop评价与dense ConvNet评价(dense和multi-crop都是评价方法)。另外,对两种评价方法的在softmax输入的平均,可以得到二者的补充。使用multi-crop评价比dense评价稍好一些。两种方法是互补的,因为其结果比随意一种都要好。可能是卷积边界条件不同的处理方式所得。
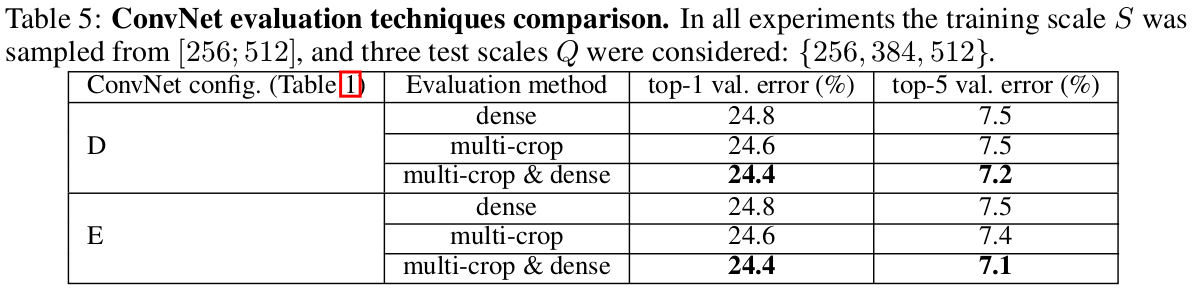
CONVNET FUSION
之前已经对单个ConvNet模型的性能进行了评价,在这部分实验,将几个不同网络模型的输出结合,对其softmax类别求平均。由于模型之间的互补性,这方法提升了性能,并且应用在AlexNet与Visualization中。
最初使用下图中7个网络的结合,达到7,3%的test error。随后,将两个multi-scale表现最好的模型D和E进行结合,用dense评价test error减为7.0%,用dense和multi-crop评价test error为6.8%。而最好的单个模型只有7.1%的error。

COMPARISON WITH THE STATE OF THE ART
CONCLUSION
在这论文中,评价了深层的卷积网络(到达19层带权值的层),这表明深层的表达对分类的准确率是有益的,随着深度的增加,ILSVRC的state-of-the-art不断改变。附录中,展示了模型对一系列任务和数据集的有效性,用更少的深层图像表达,达到甚至擦后果了复杂的识别系统。结果再一次证明了在视觉表达中,深度的重要性。