论文解读《Going deeper with convolutions》
PaperReading
Architecture
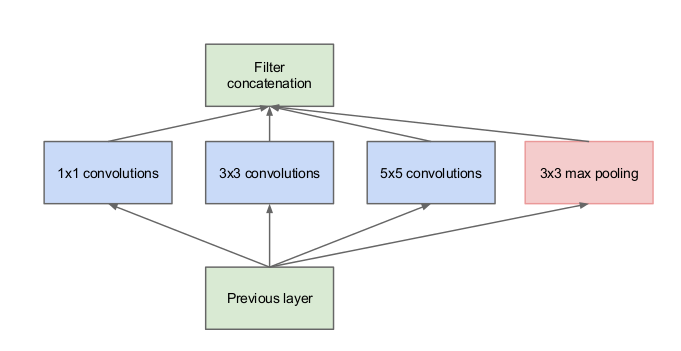
Inception architecture主要思路是基于找到在卷积视觉网络中,一个最佳的local sparse structure(局部稀疏结构)如何近似得到以及表示可用的dense部分。假设平移不变形意味着这网络将在convolutional building blocks上建立。所有的工作就是找到最优的局部结构,然后在空间上重复。有人表明了层层相连结构,在其基础上应该分析最后一层的相关统计,再高相关的单元cluster成单元组。这些clusters组成了下一层的神经元,与上一层的神经元相连接。假设前几层的每个单元对应输入图像的一些区域,这些单元组成filter banks。在较低层(靠近输入的层)相关联的单元将会关注局部区域,则意味着,我们所得到的结果将会concentrate在局部区域,其可以在下一层被1x1的卷积层所覆盖。然而,也可以人为,存在小数量在空间上更广阔的cluster,可以在更大的patch上用卷积覆盖,对于越来越大的区域,patch数量将会减少。为了避免patch相连问题,目前Inception的filter size被限制在1x1, 3,3与5x5上,然而,这个做法只是为了更便利而不是必须的。这也意味着,所提出的结构是将所有层的output filter banks结合成一个output vector,组成下一个stage的输入。另外,因为pooling操作是目前卷积网络成功的基础,因此建议在每个stage中添加可选并行的pooling,这可能会产生有益的效果。
由于Inception是对top的stack,其输出的关联统计特性必定不同:由于更高维抽象特征是更高层所得到的,其空间concentration会将降低,这表明在进入更高层后,3x3和5x5的convolution的比例将会增加。在上述模块中,有一个大问题,少量的5x5卷积将会在卷积层的top生成大量的filters。这个问题在pooling单元加入后会更明显,其输出的filters数量将会与之前stage的filter数量相同。pooling layer与convolutional layer的结合将在stage与stage之间增加不可避免的输出。甚至结构会覆盖最优sparse structure,在一些stage,这将导致计算量的增加,非常无效率。
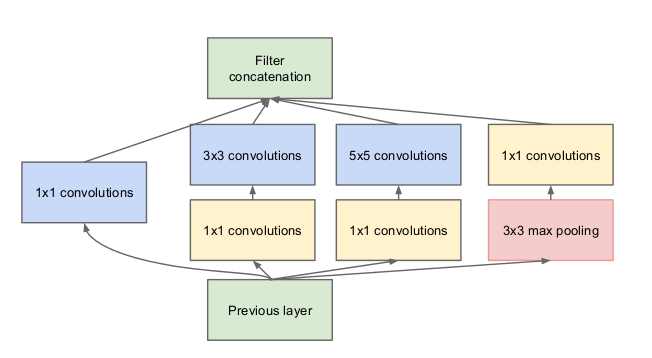
这就产生了所提出结构的第二个思路:采用dimension reduction以及projection,对于计算需要将会增加的情况。这是基于embedding的成功使用,low dimension embedding也可包含在大的patch中的许多信息。然而,embedding是通过dense,compressed形式表达信息的,其很难建模。该论文想要在大多数情况下保持representation sparse,在信号需要的时候压缩信息。因此,在3x3和5x5卷积之前使用1x1卷积减少计算量。另外,除了reduction,1x1的卷积也包含了rectified linear activation的作用。
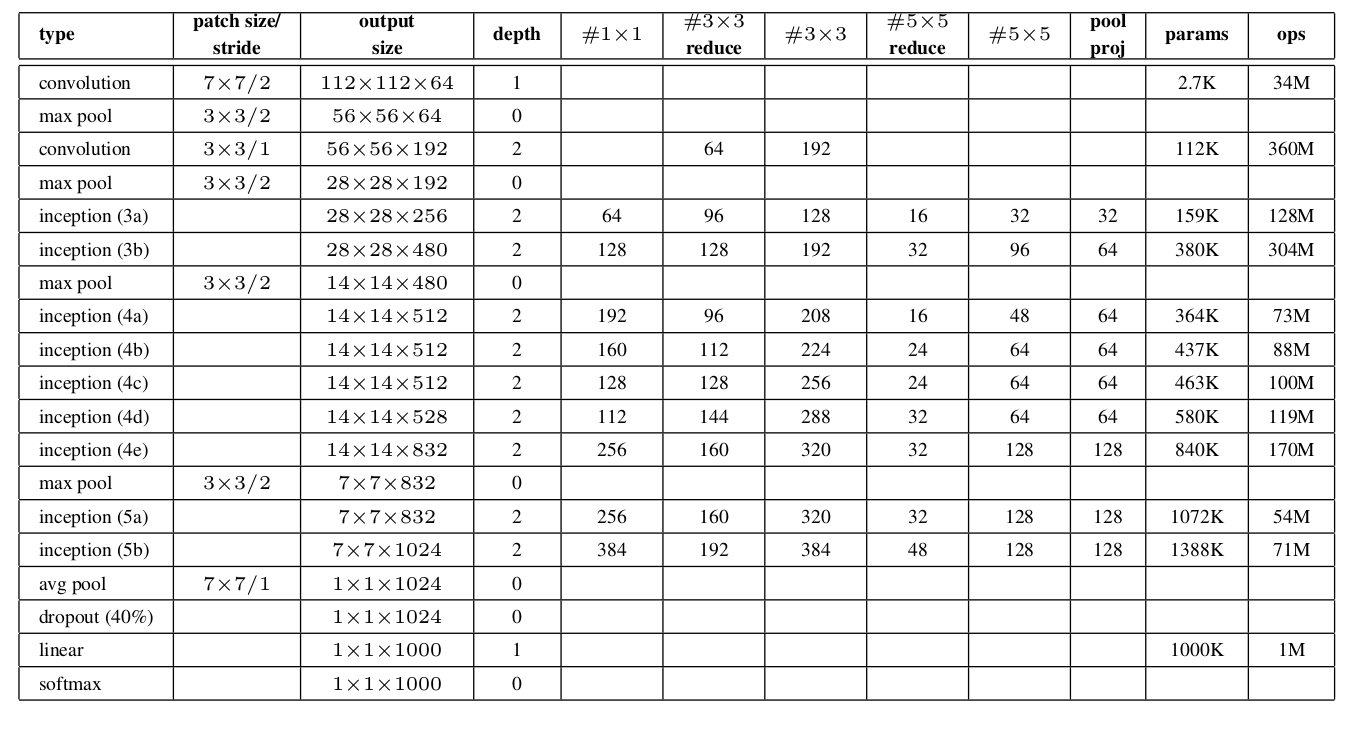
通常,在低层使用传统的convolution,在高层使用Inception。这个不是严格必须的,只是反映了目前一些基础的低效性。
这个结构一个主要的优势是允许增加每个stage单元数量,而不会产生计算量的暴增。dimension reduction的使用可以屏蔽从上一层到下一层的大量输入filters,其在卷积输入的大patch之前,先reduce dimension。另一个优势是其可以在不同scale对可视化信息进行处理再聚集,因此在下一个stage可以同时从不同scale提取特征。
这方法重发使用了计算资源,可以同时增加每个stage的width以及stages数量,而不会造成计算的难度。另一个使用inception是使用次级设计,但是计算量更小。这个方法可平衡计算资源,与没有inception的相似性能网络相比较,inception会快2-3倍,但是这个方案却需要关键的人工设计。