论文解读《Some Improvements on Deep Convolutional Neural Network Based Image Classification》
PaperReading
Abstract
该论文研究了提升基于图像分类的深度卷积神经网络的多项技术。这些技术主要包括:增加训练数据中更多的图像转换,在测试阶段增加更多的转换生成额外的预测,以及在高分辨率图像应用补充模型。
Introduction
在普通的卷积神经网络中,主要使用了pooling和normalizing层,数据转换实现增大训练数据,在测试阶段的数据转换,以及dropout避免overfitting。
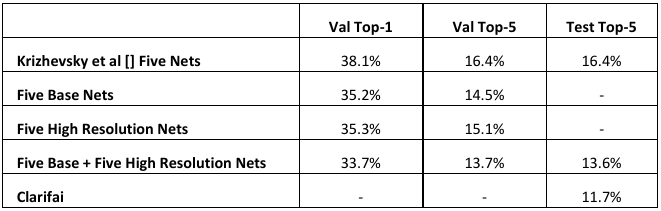
该论文在2013 ILSVRC竞赛中,取得了top5准确率为13.55%,而上一年的top5准确率为16.4%。而获得冠军的方法,取得了top准确率11.74%。
Additional Data Transformations for Training
在AlexNet中,有三种形式的图像转换方法用来提升训练集:
-
在256x256的图像中,随机取224x224的crop,获得一些平移不变性
-
使用水平翻转,获取映射不变性
-
随机增加生成光,获取亮度与微小颜色变化下的不变性
Extending Image Crops into Extra Pixels
224x224的crop是从256x256的图像中截取的。256x256图像是将原始图像最大一边rescale为256,再将另一边crop为256。这一方法大概造成大约30%的图像信息丢失。(我认为这里30%损失是指(224x224)/(256x256)=0.76,而丢失了大约30%的信息)。crop块所包含的信息比中央块中的信息量少,如果使用额外的像素信息可提升模型。
为了使用整幅图像,该论文将图像最小边rescale为256,而得到256xN或Nx256的图像。随后,随机取224x224的crop作为训练图像。这将生成大量的额外训练数据,使网络学习到更多额外的平移不变形。下图比较了平方crop与full image。与使用full image相比,crop将不会包含尾巴或耳朵。因此,使用full image避免信息的丢失。

Additional Color Manipulations
除了使用lighting noise外,论文还使用了其它的操作,包括contrast,brightness与color,通过python image library(PIL)。随机顺序使用三种操作,并且设置提升系数范围为0.5-1.5。当完成上述三种操作,再增加随机lighting noise。
Additional Data Transformations for Testing
之前的方法结合了10种图像转换的prediction,形成最终prediction。即中心与四个角的crop,再进行horizontal flip,生成10种图像转换。发现在三种尺度上的prediction提升了相连接的prediction。5 translation, 2 flips, 3 scales 与 3 views组合形成90个predictions(5x2x3x3),反而降低了准确率。为了修正这个,选择了90个predictions中的10种transformation,而如果一个包含15个prediction的子集效果将会更好。
Predictions at Multiple Scales
使用3种scales实现prediction。使用了256以及228与284。当rescale图像时,使用类似bicubic scaling的插值法,而不要使用anti-aliasing filters。
Predictions with Multiple Views
为了充分使用图像中的所有像素,论文中生成了三种不同views的图像。对于256xN图像,生成了左,中和右view,共三种256x256图像,再对每种view图像使用全部的crops,flips与scale。下图表示了图像中的三种view。

下表显示了与之前方法结果的比较,使用新的traininig和testing转换的效果。另外,也表明了用两倍的FC层的新模型不提升top5准确率。

Reducing the Number of Predictions
最终的5 crops, 2 flips, 3 scales和3 views的结合,生成了单模型90个predictions。这比之前10个predictions提升了很大的数量级。但是在实际应用中将造成延迟。因此,将predictions数量减少到可接受的数量。另外,15个predictions与90个predictions的效果相同。
Higher Resolution Models
物体在图像中有不同的scale。Higher resolution models是对base models的补充,单个high resolution model与四个额外的base models的效果相同。‘
Model Details
对于higher resolution models,使用相同的模型训练更大的图像。在448xN (Nx448)图像中取224x224crop,确保在测试时,四个角不会相互重叠。实际上 ,是在256xN (Nx256)的训练图像中,取128x128的patches,再将其rescale为224x224。
在新图像上的predictio,使用了更多的图像patches。之前5个crop在prediction中使用。因为对于higher resolution model,这些crops更少的重叠,因此增加到9个crops,增加了上下左右边的中心位置。这使每个model的总prediction数目上升到162个(9 crops x 2 flips x 3 scales x 3 views)
Results
最终提交的分类系统由10个网络组成,5个基础模型与5个high resolution模型。与上一年的top5的16.4%有提升, 但是比不上最好top5的11.7%。