


《Factors in Finetuning Deep Model for object detection》论文解读
Abstract
在目标检测中,每类的样本数目,呈现长尾性质(即分布非常不均匀)。如果使每类的样本数目更平均,将会使结果更好。每类物体在视觉上都具有很明显的区别,则该论文将视觉上相似的物体类聚成一组,再从这些组中分别学习特征表达。论文提出了分层次的学习方案。在大数量组中学习到的知识将会传递给其子组。
Introduction
论文作者观察到两个特点:
-
长尾性质。长尾现象:一些类的物体经常出现,而大多数类物体偶尔才出现。分析了以下长尾性质在ImageNet的物体检测数据集的影响。在特征学习过程中,拿出40%的正样本使类间样本数目更平均,检测准确率有所提高。
-
对特定类别学习特定特征表达。多目标类别的检测是由多任务组成的。每个类别的检测是一个任务。目前的深度学习对所有的类别共享一个特征表达方法。不同物体有不同视觉特征,而所学习到的特征表达也应该只注重特定类别。
该论文的贡献:
-
实验研究和分析了对影响finetuning有效性的因素。研究的fators包括:在model的不同层上finetune的影响,长尾性质的影响,训练样本数目的影响,不同物体类别的子集的有效性,训练数据子集的影响。
-
级联的分层特征学习方法。物体类别被分为不同的组。而不同的方法用来检测不同组中的物体类别,模型逐渐关注物体类别中特定的组。
在论文中,不同的物体类别使用不同的深度模型,因此对这些物体类,学习到了具有区别性的表达。在普通的多模型组合中,一个物体类别中的检测分数是由多个不同参数的深度模型中得到的。然而,在论文中的方法,一个物体类别检测分数是只由一个模型得到。
Factors in finetuning for ImageNet object detection
Baseline model
Region proposal.论文中使用selective search来得到候选框,默认情况下,使用bounding box rejection方法,因此只有大约6%的候选框被保留。
Training and Testing data.ImageNet detection数据集被分为3份:train13,val和test。train14为额外数据。在training和validation中使用val,则将val分为val1和val2。train13,val1和train14用来训练。如果无说明,则selective search得到额外正确的bounding boxes和负的bounding boxes,从train13和train14得到ground truth正bounding boxes。
Network, pretraining, and finetuning.主要使用GoogLeNet来完成finetuning。在finetuning阶段,除了1000-way分类层用200+1-way的softmax分类层替换(1为背景),其余CNN结构不变
SVM learning.在学习特征后,one-vs-rest线性SVM来得到每个类别的检测。在不同的训练数据准备的前提下,SVM保持不变。
Summary.用bounding box annotations预训练,在val2上GoogLeNet得到40.3%的mAP,深度模型用200+1的softmax loss微调,线性SVM作为分类器。
Investigation on freezing the pretrained layer in finetuning
固定了GoogLeNet的某几层参数,只finetune剩下层的参数。如果固定了所有11个模块,使用原来的特征学习SVM,则mAP为33.0%,比所有模块都finetune的40.3%更差。底层生成low level features,已被很好地预训练。当固定越高层,mAP下降越快。因此对高层的finetune对decection效果有更多的影响。
Investigation on training data preparation
Investigation on different subset of training data
训练数据有三个不同的子集,其实验结果如下表。

The long-tail property
59.5%的ground-truth样本是从大样本数量的类别中提取的。为了使样本数量分布更均匀,在train13中样本数目被限制在1000以内。
如果鸟类有16000个样本,而仓鼠只有16个样本,那么从鸟类中得到的梯度的规模大约是从仓鼠中得到的梯度的1000倍。从鸟类的深度模型中学习到的特征不一定比仓鼠的重要。
Experimental results on the long-tail property
N+正样本/bounding-boxes,N-负样本/bounding-boxes。设置三种方案:
-
Rand-pos.N+正boxes通过随机采样减少为N’+box。负boxes保持不变。
-
Rand-all.正负box同时减为N’+和N’-。
-
Pesudo-uniform.类别中样本超过max的只留下Nmax,少于Nmax的不变。
在第一种和第二种方案中,长尾性质不变。实际上,第三种方案,只需要相当于第一种方案一半的正样本数目。
实际结果表明,类别样本的均匀比长尾性质的样本表现更好。
Experimental study on subsets of object classes
使用50,100和150类来finetune得到最大准确率,再用这模型对200类提取特征,用来对SVM学习。50类的finetune比另外150类没有使用finetuning的模型效果更好。如果剔除样本最少的50类,用150类最多样本的物体来finetune,准确率比200类少0.2%。
由此可见,类别数量对finetuning替身mAP是关键因素。
Cascaded hierarchical feature learning for object detetion
Grouping objects into hierarchical clusters
200类目标被分为多个层次的组别。第一层只有1组,200个类;第二层有4组,每组50个类;第三层有7组,每组29个类;第四层有18组,每组11个类。
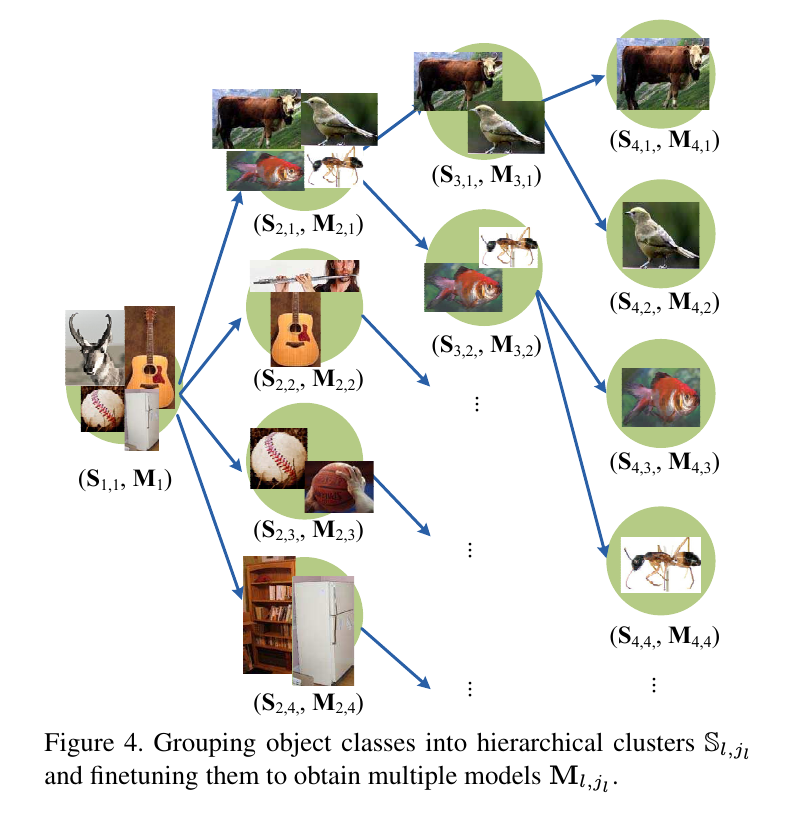
Our approach at the Testing Stage
测试阶段,测试样本从是根到叶的尾端。
Hierarchitecal Feature Learning
对节点(l,j_i),深度模型(M_l,jl)从从M_l-1作为初始点finetune得到。(M_l,jl),正样本数限制在(S_l,jl)的类标签,富样本接收其父节点。因此只有目标类别中的一个自己用来finetune(M_l,jl)。另外,当finetune深度模型时,使用multi-class cross-entropy来学习特征表达。
Experimental results on the Hierarchical Feature Learning
Ablation study
Investigation on different clustering methods
下标表示不同的分组方法对检测准确率的提高,除了随机将目标类别为4个组。

Investigation on the influence of hierarchy level
分层特征学习中,level L,即分组层数的影响,其结果显示在下表。
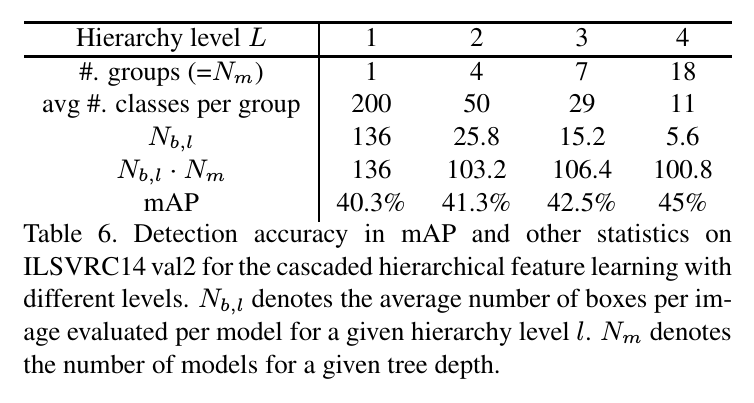
当level为4时,对每个bounding box有18个模型要评判。看起来数量很多,但是通过级联,可以排除每个模型中很多的boxes,平均每个模型只需要评判每张图像的5.6个boxes。
Investigation on the finetuning strategy
从不同层不段finetune得到结果。